How AI weather models like ECMWF-AIFS and GraphCast work
Original article: https://twitter.com/Brady_Wx/status/1769910256354627891
GraphCast: Learning skillful medium-range global weather forecasting
I see a lot of people posting false information about AI weather models like ECMWF-AIFS and GraphCast. This is brand new technology, so misunderstandings are to be expected. I'll try to explain how they work in way that is simplified and easy to understand. This is a bit over-simplified, but should be sufficient to help weather enthusiasts, storm chasers, etc understand how these models work to an extent.
These models aren't weather models designed by AI. They aren't ChatGPT wrappers. In fact, they aren't even related to that "kind" of AI (Large Language Models). These models use a somewhat similar underlying 'architecture', but do not use human-like logic in any way. "Machine-Learning" is probably an easier way to understand these models than the term "AI".
So, briefly, I will describe how neural networks work in general.
Problem
Imagine you are trying to predict whether or not a severe thunderstorm is likely at a precise location (lets say Amarillo Tx), and you want to build an extremely basic neural network for this task. This basic neural network is called a multi-layer perceptrton (MLP).
Features
Some features to consider at this location would be dew-point, srh, wind shear, cape.. we'll leave it at those 4 for this example. So our MLP will be taking the DP, srh, 500mb wind shear, and CAPE at this location and it will be outputting the probability of a severe thunderstorm. The model will need to somehow learn what combinations of DP,srh,ws, and cape generally mean severe thunderstorms and what combinations do not.
Let's say we've collected 100 data points for Amarillo Texas (so 100 days of data). In 50 of those, a severe thunderstorm happened, and in the other 50 there weren't any severe thunderstorms. So what we now have is 100 data points where each data point contains the DP, srh, 500mb wind shear, and CAPE in Amarillo on that day, as well as whether or not a severe thunderstorm occurred. So we have our training data and we are ready to feed into MLP.
Model hidden layers
The MLP will go datapoint-by-datapoint, for each datapoint the data will be input and will enter the first "hidden layer". In this hidden layer, the model applies some random multiplication (weights) and addition (bias) to each input, n number of times (the number of "neurons" in this hidden layer). Each neuron is then connected to the neurons in the next hidden layer. The number of hidden layers is the "depth" of the model and is customizable by the model engineer. More complex models require more neurons and more depth, to compensate for the complexity of the issue at hand.
In each hidden layer, the neurons from the previous layer are fully connected to the neurons of the current layer, weights (multiply) and biases (add) are applied, and then they move to the next layer. A special function is applied between layers to ensure that the model is able to learn non-linearity (not really relevant to a simple discussion here). When the data arrives at the final/output layer, the biases/weights from the final hidden layer are all congealed into a single neuron. A special function is applied here which adjusts all of the data into a single value between 0 and 1, and that is your probability.
Training
The model will begin training with random weights and biases but with each datapoint will propagate backwards to try to "figure out" how to adjust the weights and biases to reduce the error. After many datapoints and epochs (iterations over the same data), the model (if it is well designed with quality, diverse data) will be able to be applied to new data (only inputs) and output realistic probabilities (outputs).
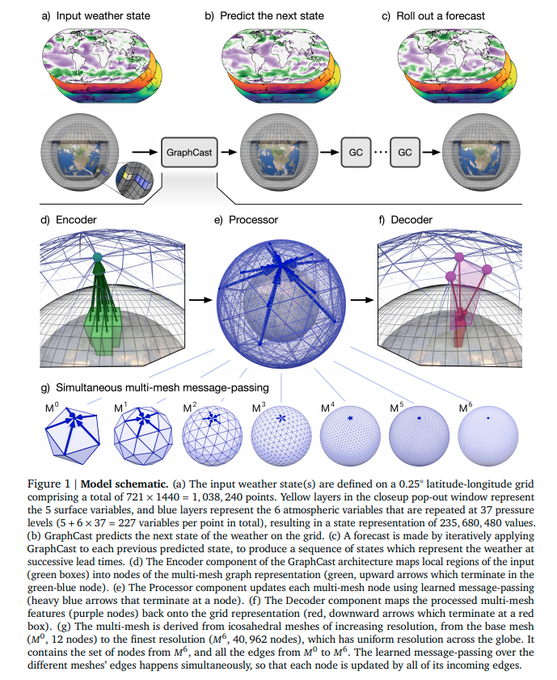
So how exactly do these new AI/ML models work? Both AIFS and GraphCast use an architecture called encoder-processor-decoder Graph Neural Networks. This means that the model takes the input data and puts it through 3 steps (encoder, processor, decoder). I will mostly focus on GraphCast as it is open source.
Encoder gridpoints
In the first step, the encoder, the models take initial conditions (various meteorological fields such as temperature, geopotential heights, humidity, and more) across the globe and "encode" these datapoints onto a mesh grid (a grid where gridpoints are equidistant from one another) and connect each gridpoint to other gridpoints that are nearby as well as far away. This mapping is done by a neural network, which just means that the model is trained on how to make these connections most efficiently. Each gridpoint is now considered a "node" in the graph with "edges" connecting them to gridpoints near and far (7 levels of resolution reduction allow for connections near and far (high resolution and low resolution)).
Forward-propagating
"Connected" in this context just means that the program is informing the model that the gridpoints are connected and how they are connected. So the gridpoints (and their data) are connected, now what's next? The model enters the "processor" stage. In the processor stage, the model passes data between connected gridpoints 16 times. When a node (or gridpoint) receives information from a connected node, it updates its values and pushes data to the connected gridpoints. This message (or data) exchange occurs 16 times. The changes that each gridpoint applies is dependent on the data it is receiving from neighboring gridpoints, and this is entirely dependent on the training.
Back-propagating and Decoder gridpoints
The final step is the "decoder" stage. In this stage, the data is plotted from the abstract processing stage, where it is split between various grid resolutions, back to the original 0.25deg lat-lon grid. This mapping is done through a single-layered graph neural network (the model simply learns how to map the data back to the original lat-lon grid). In training, the model compares the output to the expected output (target data based on past analysis data).. if the difference is huge, the model goes backwards through the steps and tries to adjust the values so that the error is reduced. It does this over and over again for each past event... and then goes over all of the events again likely dozens to hundreds of times. This allows the model to learn all of these various "trainable" factors (connections between gridpoints, how to change the data based on neighboring data, how to plot the data back to the original latlon grid, etc)..
Chained forecast
This is only for a 6hr forecast. The outputs from the 6hr forecast are then fed back into the model as inputs, producing a fresh 6hr forecast (total of 12hrs).. these forecasts are continuously chained together into the future indefinitely.. usually 240hrs currently. Eventually, the data becomes oversmooth and unrealistic.
So these models are very complex... a lot of that is simplified. If you'd like a deeper dive into this, I suggest reading the full paper on GraphCast published by google deepmind.
Test
Btw: these models have been extensively tested with published verification data. They score better on every tested metric compared to ECMWF, GFS, and every other physics model. This includes with severe weather such as tropical cyclones.